FM详解
本文共 476 字,大约阅读时间需要 1 分钟。
FM因子分解机和矩阵分解
FM介绍
FM分解机是在线性回归的基础上加上了交叉特征,通过学习交叉特征的权重从而得到每个交叉特征的重要性。这个模型也经常用于点击率预估。
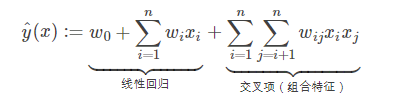
其中,n代表样本的特征数量,x_i是第i个特征的值,w_0,w_i,w_ij是模型参数
训练w_ij需要大量非零的x_i和x_j,而样本稀疏的话很难满足,太稀疏可以引进矩阵分解的技术,这也是为什么叫做分解机的原因
对权重进行分解:

二次项化简后后 :参考
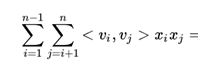
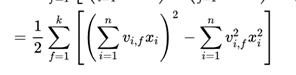
此时_if的训练只需要样本的x_i特征非0即可,适合于稀疏数据。
FFM:
考虑了稀疏问题,每一维特征都对其他不同类型特征每一种field、学习隐向量
参考:
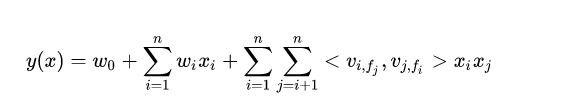
解决数据稀疏问题,提出FFM,onthot编码同样的field不分开 (男女放在同一列不分成两列)
为了使用FFM方法,所有的特征必须转换成“field_id:feat_id:value”格式,field_id代表特征所属field的编号,feat_id是特征编号,value是特征的值

复杂度
FM通过合适的推导,训练/预测复杂度是线性的。而FFM的复杂度是二次方的。
转载地址:http://mlhdi.baihongyu.com/
你可能感兴趣的文章
Django框架全面讲解 -- Form
查看>>
socket,accept函数解析
查看>>
今日互联网关注(写在清明节后):每天都有值得关注的大变化
查看>>
”舍得“大法:把自己的优点当缺点倒出去
查看>>
[今日关注]鼓吹“互联网泡沫,到底为了什么”
查看>>
[互联网学习]如何提高网站的GooglePR值
查看>>
[关注大学生]求职不可不知——怎样的大学生不受欢迎
查看>>
[关注大学生]读“贫困大学生的自白”
查看>>
[互联网关注]李开复教大学生回答如何学好编程
查看>>
[关注大学生]李开复给中国计算机系大学生的7点建议
查看>>
[关注大学生]大学毕业生择业:是当"鸡头"还是"凤尾"?
查看>>
[茶余饭后]10大毕业生必听得歌曲
查看>>
gdb调试命令的三种调试方式和简单命令介绍
查看>>
C++程序员的几种境界
查看>>
VC++ MFC SQL ADO数据库访问技术使用的基本步骤及方法
查看>>
VUE-Vue.js之$refs,父组件访问、修改子组件中 的数据
查看>>
Vue-子组件改变父级组件的信息
查看>>
Python自动化之pytest常用插件
查看>>
Python自动化之pytest框架使用详解
查看>>
【正则表达式】以个人的理解帮助大家认识正则表达式
查看>>